
De juiste hoeveelheid
op het juiste moment.
Productieplan voor optimale productbeschikbaarheid.
Verhoog je winst door volle schappen en verse producten — en hou voedselverspilling onder controle.
-min.webp)
Complexe uitdagingen. Intelligente AI-oplossingen.
Verhoog efficiëntie, optimaliseer processen en zet inzichten om in resultaat.
etcetera
van het drukken van goederen


marge na contributie

Entscheidungen
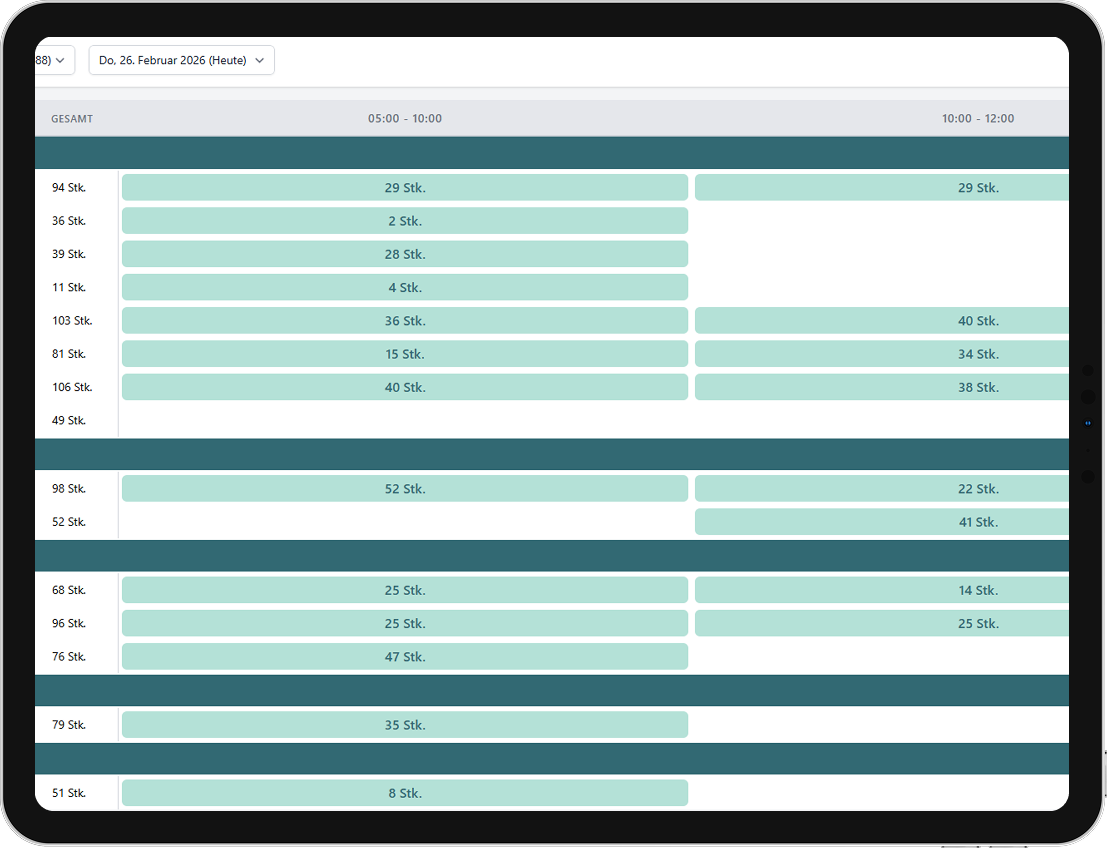
Voorkom voortijdige uitverkoop en verminder verspilling
Gerichte sturing van productbeschikbaarheid voor meer winst
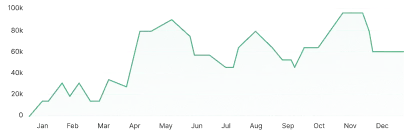
In-store autopilot voor de juiste hoeveelheid op het juiste moment.
Het productieplan biedt intra-dag, AI-gedreven voorspellingen om optimale beschikbaarheid van producten te garanderen. Door de voorspellingen meerdere keren per dag te actualiseren, stelt het winkelteams in staat om producten met precisie te produceren en aan te vullen — precies op het moment dat het ertoe doet.
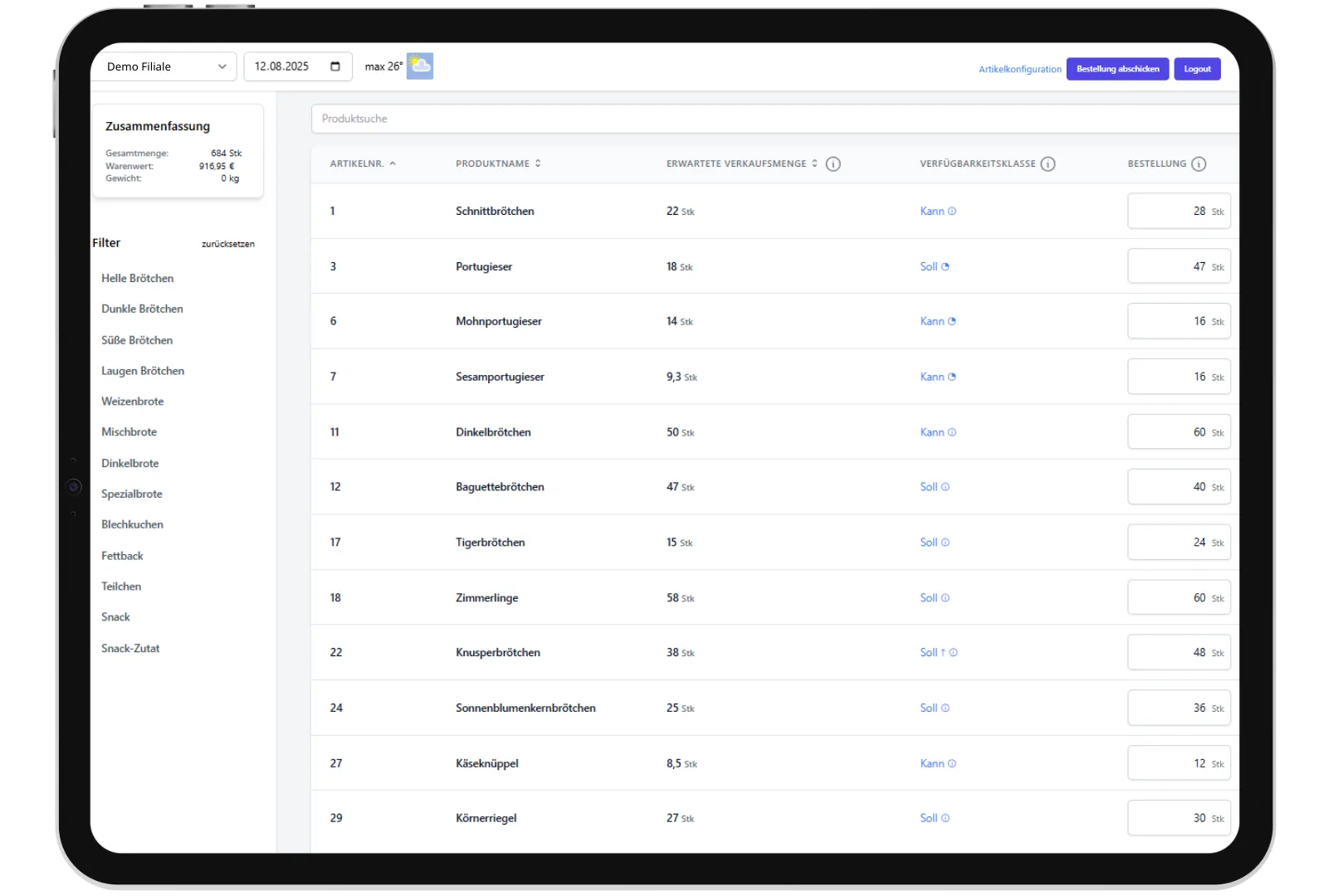
AI-gestuurde vraagvoorspellingen voor nauwkeurige bestellingen.
De besteloptimalisatie levert dagelijkse, AI-gedreven vraagvoorspellingen die volledig zijn afgestemd op de behoeften van je winkel. Deze prognoses zorgen voor de juiste hoeveelheden in het magazijn, bij leveranciers of in centrale hubs - volle schappen met minimale voedselverspilling en slechts één bestelling per dag.
10x
Rendement op investering
.webp)



.webp)

Winst en efficiëntie verhogen — neem nu contact op
Met foodforecast leid je jouw bedrijf naar een duurzamere toekomst. Samen revolutioneren we de voedselproductie en verminderen we voedselverspilling. Ons doel: samen een positieve bijdrage leveren aan milieu en maatschappij — en tegelijk je winst vergroten.
Antwoorden
op je belangrijkste vragen
Ja, in de voorspellingen wordt rekening gehouden met seizoensschommelingen en feestdagen
Onze AI-oplossing loont vrijwel onmiddellijk, omdat onze kunstmatige intelligentie onmiddellijk klaar is voor gebruik dankzij de training van historische gegevens. Dit betekent dat bedrijven geen lange trainingsperioden of uitgebreide implementatiefasen hoeven te doorlopen om te profiteren van de voordelen van de oplossing.
Dit is een doorslaggevend voordeel van onze AI-oplossing, omdat de AI al heeft geleerd hoe de verkoop zich gedraagt op basis van historische gegevens. De historische gegevens worden gebruikt om AI te trainen en nauwkeurige voorspellingen te doen over de vraag naar goederen en om analyses te maken. Op deze manier kunnen gebruikers onmiddellijk profiteren van de inzichten die uit deze analyses zijn verkregen.
Bovendien maakt de oplossing het mogelijk om trends en patronen te identificeren die eerder misschien onopgemerkt zijn gebleven. Dit kan betekenen dat beslissingen sneller kunnen worden genomen, wat op zijn beurt leidt tot een onmiddellijke stijging van de omzet.
Een ander aspect dat bijdraagt aan onmiddellijke winstgevendheid is de gebruiksvriendelijke interface en intuïtieve bruikbaarheid van de oplossing. Medewerkers hebben daardoor nauwelijks tijd nodig om vertrouwd te raken met de software. De training is meestal kort en efficiënt, wat betekent dat het team snel aan de slag is om van de oplossing te profiteren.
Onmiddellijke winstgevendheid komt ook tot uiting in de mogelijkheid om middelen efficiënter te gebruiken. Door een nauwkeurige verkoopplanning kunnen bedrijven overtollige voorraad vermijden, de voorraadkosten verlagen en de efficiëntie van hun toeleveringsketens verbeteren.
Nee, er is geen speciale voorkennis vereist om ons systeem te gebruiken. De bediening is bewust eenvoudig, zodat u snel en eenvoudig kunt beginnen met het voorspellen van werk. Ons doel is om het proces zo gebruiksvriendelijk mogelijk te maken, zodat u zich kunt concentreren op uw kernactiviteiten zonder dat u zich vertrouwd hoeft te maken met ingewikkelde technische details.
Eenvoudig te gebruiken:
De gebruikersinterface en functies van ons systeem zijn intuïtief en duidelijk gestructureerd. Zelfs zonder diepgaande IT-kennis kunt u de prognosegegevens eenvoudig bekijken, analyseren en integreren in uw bestelprocessen. De belangrijkste functies zijn zo ontworpen dat ze met een paar klikken toegankelijk zijn en dat de evaluatie van prognoses geautomatiseerd is. Dit betekent dat u zich niet bezig hoeft te houden met het handmatig berekenen van bestelhoeveelheden of complexe gegevensanalyses.
Ondersteund door onze 24-uurs ondersteuning:
Mochten er vragen of uitdagingen rijzen, dan is er altijd een persoonlijke contactpersoon beschikbaar om u te helpen. We bieden uitgebreide ondersteuning, van de eerste installatie tot het dagelijks gebruik van het systeem. Indien nodig helpt ons team u ook om het systeem aan uw individuele vereisten aan te passen en ervoor te zorgen dat alles soepel verloopt.
Kortom, je hebt geen speciale voorkennis nodig. Ons systeem is zo ontworpen dat het voor iedereen gemakkelijk te begrijpen en toegankelijk is. Tegelijkertijd kunt u altijd rekenen op ons team van experts als u hulp nodig hebt. Op deze manier zorgen we ervoor dat u vanaf het begin optimaal met de voorspellingen kunt werken, zonder lange trainingsperioden of technische hindernissen.
Om een effectief en krachtig machine learning-model te ontwikkelen, is de selectie en kwaliteit van trainingsgegevens cruciaal. Alleen uw verkoopgegevens zijn relevant voor AI-training. Deze gegevens omvatten gedetailleerde informatie over het aantal en het type producten dat gedurende verschillende perioden is verkocht. Verkoopgegevens zijn essentieel omdat ze patronen in het koopgedrag van klanten aan het licht brengen, seizoensschommelingen aan het licht brengen en trends identificeren die cruciaal zijn voor het voorspellen van toekomstige verkopen en het optimaliseren van voorraadniveaus.
1. Relevantie en kwaliteit van gegevens:
Het is belangrijk dat de gegevens nauwkeurig en betrouwbaar zijn. Onnauwkeurige of misleidende gegevens kunnen het model vervormen en tot onjuiste resultaten leiden. Datakwaliteit omvat ook de consistentie, volledigheid en tijdigheid van gegevens.
2. Diversiteit aan gegevens:
Diversiteit aan functies: Om een robuust model te bouwen, is het belangrijk om verschillende kenmerken (kenmerken) te hebben die betrekking hebben op verschillende aspecten van het probleem dat wordt opgelost.
Verschillende voorbeelden: Een diverse dataset zorgt ervoor dat het model niet alleen wordt getraind op specifieke patronen of stereotypen. Dit helpt overfitting te voorkomen en verbetert het vermogen van het model om te generaliseren naar nieuwe, onbekende gegevens.
3. Annotatiegegevens:
Etikettering: Gelabelde gegevens zijn vereist voor algoritmen voor leren onder toezicht. Dit betekent dat elk datapunt moet worden voorzien van het juiste antwoord of de juiste classificatie.
Kwaliteit van het etiket: De nauwkeurigheid van de etiketten is cruciaal. Onjuist gelabelde gegevens kunnen resulteren in een onnauwkeurig model. Het is belangrijk dat etiketten consistent en nauwkeurig zijn, vaak gegarandeerd door handmatige verificatie of geautomatiseerde kwaliteitsborgingsprocessen.
4. Gegevensvolume:
Voldoende hoeveelheid gegevens: Over het algemeen geldt: hoe meer data, hoe beter. Een grote hoeveelheid gegevens helpt het model betere patronen te herkennen en complexere relaties te begrijpen. Er moet echter ook een evenwicht worden gevonden tussen de hoeveelheid gegevens en de verwerkingskosten.
Saldo van de klassen: Voor classificatieproblemen is het belangrijk dat de verschillende klassen op een evenwichtige manier in de dataset worden weergegeven om een evenwichtig model te garanderen.
Desondanks moeten alle gegevens altijd relevant, van hoge kwaliteit, divers en in voldoende hoeveelheden beschikbaar zijn om een krachtig model te trainen. Zorgvuldige gegevensverzameling en -voorbereiding is daarom essentieel voor het succes van machine learning.
Om analyseredenen exporteren we ook de retour- en leveringshoeveelheden en de stamgegevens van het artikel.
- Data van terugkomst: Deze gegevens geven het aantal onverkochte producten weer. Dit helpt om de productkwaliteit en klanttevredenheid te verbeteren. Retourgegevens kunnen ook helpen bij het identificeren van patronen die kunnen wijzen op problemen in het bestelproces, wat op zijn beurt helpt om toekomstige retouren te verminderen.
- Gegevens over de leveringshoeveelheid: Informatie over de geleverde hoeveelheden goederen is essentieel om de bevoorrading te plannen en knelpunten of overvoorraden te voorkomen. Deze gegevens helpen om nauwkeurigere voorspellingen te doen over toekomstige bestellingen en zo de toeleveringsketen efficiënter te maken.
- Stamgegevens van het item: Deze bevatten gedetailleerde informatie over elk product, zoals productbeschrijvingen, categorieën, prijzen, maten en kleuren. Stamgegevens van artikelen zijn belangrijk om producten correct te classificeren en om relaties tussen verschillende kenmerken en verkoopcijfers te identificeren. Ze vormen de basis voor een goed onderbouwde analyse.
Door deze gegevenstypen te combineren, kunnen gefundeerde beslissingen worden genomen, niet alleen op basis van verkoopcijfers, maar ook op andere aspecten van de toeleveringsketen. Uiteindelijk resulteert dit in verbeterde efficiëntie, kostenbesparingen en een hogere klanttevredenheid.
Onze methodologie zorgt ervoor dat alle relevante gegevens worden verzameld en geanalyseerd om de best mogelijke resultaten te bereiken. De gegevensbescherming en gegevensbeveiliging worden altijd gehandhaafd, zodat uw gegevens veilig en vertrouwelijk blijven.
De doorlooptijd voor de implementatie van foodforecast is afhankelijk van verschillende factoren, waaronder de complexiteit van uw systemen, het aantal locaties dat moet worden geïntegreerd en de specifieke vereisten van uw bedrijf. Het duurt gewoonlijk ongeveer 4 tot 8 weken vanaf het eerste interview met deskundigen tot de start van de pilot of de verstrekking van prognoses.
1. Discussie met deskundigen en behoefteanalyse:
De eerste stap is een gedetailleerde consultatie waarin onze experts samen met u uw huidige uitdagingen en doelstellingen analyseren. Dit bepaalt welke modules en functies van foodforecast de grootste toegevoegde waarde bieden voor uw bedrijf. Op basis van deze behoefteanalyse creëren we een individueel concept dat is afgestemd op uw behoeften. Deze fase legt de basis voor de volledige implementatie en is cruciaal om latere vertragingen te voorkomen.
2. Technische voorbereiding en integratie:
In deze fase wordt de technische verbinding van foodforecast met uw bestaande systemen voorbereid. Dit omvat de integratie van interfaces en de configuratie van de datastromen die nodig zijn voor prognoses. De duur van deze stap is sterk afhankelijk van hoe complex uw IT-landschap is en hoeveel aanpassingen er nodig zijn.
3e pilotfase:
Na de technische installatie start de pilotfase. Gedurende deze periode worden de voorspellingen in een reële omgeving getest en indien nodig aangepast. Deze testfase is belangrijk om ervoor te zorgen dat de voorspellingen nauwkeurig zijn en naadloos kunnen worden geïntegreerd in uw workflow. Tijdens de pilotfase zullen onze experts u ondersteunen en helpen bij het finetunen.
4e planningsfase:
In deze fase werken we samen om erachter te komen hoe onze modules de grootste toegevoegde waarde creëren voor u en uw bedrijf. Op basis hiervan stellen we uw individuele pakket samen. We staan altijd klaar om u ondersteuning en verdere verbeteringen te bieden om een soepele werking te garanderen.
Afhankelijk van de uitgangssituatie vereist de introductie van foodforecast een totale doorlooptijd van 4 tot 8 weken. Deze periode omvat planning, technische uitvoering, proeffase en definitieve lancering. Vroegtijdige coördinatie is cruciaal voor een soepele uitvoering, zodat alle noodzakelijke stappen optimaal kunnen worden gepland en uitgevoerd. Als aanvullende aanpassingen of complexe integraties nodig zijn, kan het proces ook langer duren. We begeleiden je in ieder geval nauwgezet door alle fases en zorgen ervoor dat je zo snel mogelijk kunt profiteren van de voordelen van foodforecast.